July 12, 2001 Update
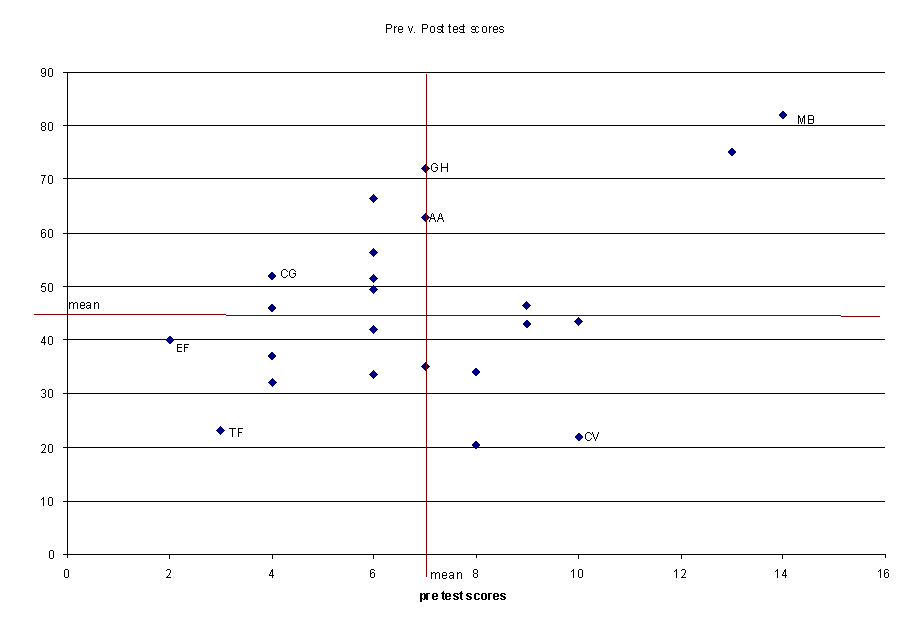
Some errors were discovered in the data and data analysis this week, which has necessitated redoing the analyses completed during the last couple of weeks. The scatter plot of the post test scores vs. the pretest scores was redone after an error was discovered in computing the total pre test score.
The six learners whose data are being scrutinized most closely are labeled. The student represented by the circled point labeled EF may be added to the group being closely analyzed because EF began using BioLogica with the lowest pre test score, but scored very near the mean on the post test; a success story. Three of the learners (MB, CV, TF) are still interesting by virtue of the quadrants in which their scores are located. With the revised pretest scores, both GH and AA are instances of learners who began using BioLogica with pretest scores at the mean and emerged with post test scores near the top of the group. CG remains interesting due to difficulties with reading.
Changes in the pre test scores and some vagaries in the way Excel performs time calculations also necessitated a revision of the analysis of the average index of interaction demonstrated by the six students. Last week we introduced this construct as level of engagement. After some discussion within our group, we have decided to use the term index of interaction because it more accurately describes the nature of the construct. Index of interaction is calculated by dividing the length of time (calculated by hand from the data log) by the length of the data log (a rough measure of number of interactions between user and activity). Table 1 and the chart that follows make obvious the wide range of behavior captured by the logs and test scores. Remember that the data on which these figures are based must be obtained by hand coding and calculating times from the data logs. Hence, there are points only for the 6 six students whose data logs have been analyzed to date.
Table 1. Learner data
|
learner |
pretest rank |
posttest rank |
change in rank |
total time |
index of interaction |
# activities logged |
|
CV |
4 |
22 |
-18 |
1:44 |
0.15 |
11 |
|
MB |
1 |
1 |
0 |
5:25 |
0.39 |
10 |
|
TF |
22 |
21 |
1 |
3:44 |
0.40 |
11 |
|
AA |
10 |
5 |
5 |
3:17 |
0.44 |
12 |
|
GH |
9 |
3 |
6 |
4:20 |
0.48 |
11 |
|
CG |
18 |
7 |
11 |
7:22 |
0.86 |
8 |
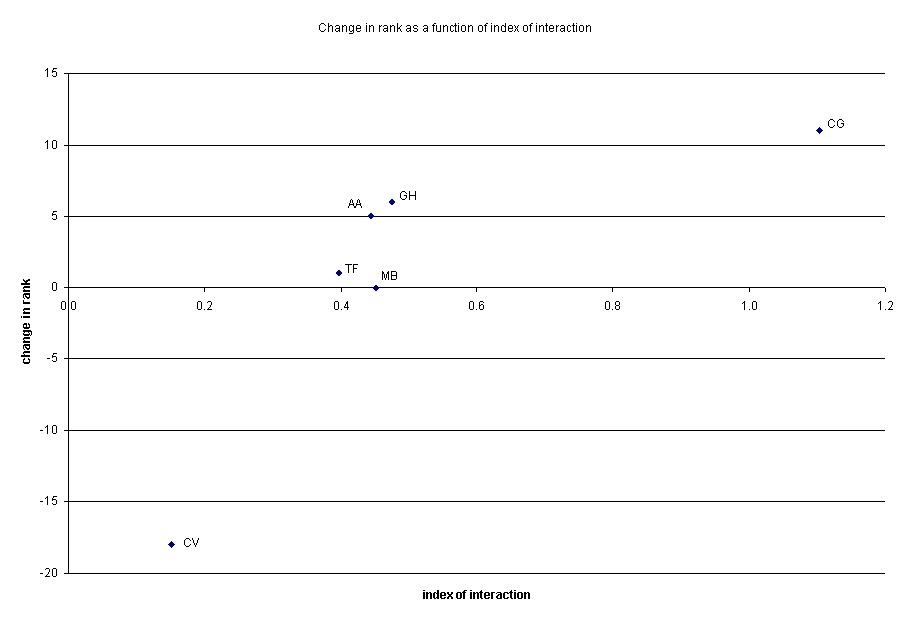
Although there seems to be a wide range in the index of interaction among these learners, the measure by itself provides only part of the story about the differences in these students. If we look at the extreme cases (CV and CG) the index of interaction seems to correlate with their change in rank. However, if we exclude those extremes, the remaining four students are clustered between 0.4 and 0.5. Perhaps this is signals a productive range of interaction with the extremes signifying unusual cases. Until we can process the data logs online, these are at best tentative hypotheses awaiting testing with more data against learning gains.
We can also analyze the data across activities. Pooling data for individual activities across the six students yields Table2.
Table 2. Comparing activities.
|
Activities |
LOT Range (minutes) |
Ave LOT |
Ave LOR |
Ave IOI |
||
|
1 |
Introduction |
3 - 42 |
0:22 |
40 |
0.5 |
|
|
2 |
Rules |
1 - 180 |
0:39 |
99 |
0.3 |
|
|
3 |
Meiosis |
11 - 38 |
0:18 |
27 |
0.6 |
|
|
4 |
Inheritance |
2 - 9 |
0:04 |
5 |
0.9 |
|
|
5 |
Monohybrid |
11 - 34 |
0:18 |
77 |
0.3 |
|
|
6 |
Mutations |
3 - 34 |
0:24 |
52 |
0.8 |
|
|
7 |
Mutations2 |
14 - 104 |
0:32 |
61 |
0.6 |
|
|
8 |
HornsDilemma |
3 - 12 |
0:07 |
55 |
0.2 |
|
|
9 |
Dihybrid |
1 - 23 |
0:13 |
35 |
0.4 |
|
|
10 |
Sex-Linkage |
4 - 59 |
0:26 |
40 |
0.6 |
|
|
11 |
Scales |
6 - 23 |
0:12 |
59 |
0.2 |
|
|
12 |
Plates |
1 - 5 |
0:26 |
40 |
0.6 |
Where,
LOT = length of time calculated from the data log of the activity
LOR = length of data log (a rough measure of the number of entries)
IOI = index of interaction = LOT/LOR
From this analysis we can develop some idea how long students spent on each activity, but we cannot do much more than that. Data logs are generated by the same script that governs learners' interactions with the representations in an activity. Since we do not yet have consistent specifications for writing data logging events into a script, there is quite a large variation in the nature and extent of the logs generated by different activities.
Next steps involve the creation of narratives for individual students. These narratives will trace the development of conceptual understanding from the pretest to the post test through analysis of the data logs and interviews. The process of creating these narratives will be used to finalize methods for analyzing the large data sets collected in the various school implementations. The narratives themselves will be used to contextualize and illustrate our quantitative results.
Please visit Teaching Genetics with Dragons for our latest related resources.